
始めに
こんにちは、サーバエンジニアのnekoです。
GWは皆さん如何お過ごしでしたでしょうか?
私はわりとイベントが多く
忙しく過ごしておりました。
さて、今回はDB(データベース)のお話をしていこうと思います。
よく名前は耳にすると思いますが、実際どのように扱っているか?
を紹介していこうと思います。
概要
DBとはデータをまとめて管理するための物で
実際のデータは下記のような表のイメージが近いです。このような表をテーブルと呼びます。
| ID | タイトル | 著者 | 出版社 | 発売日 |
| 1 | クロスプラススタジオの歴史 | 〇〇 | クロプラ出版 | 2022-05-10 |
| 2 | ゲーム大好き | neko | ゲーム出版 | 2021-04-01 |
| 3 | サーバーエンジニア入門 | neko | クロプラ出版 | 2022-01-01 |
「ID」などの各項目をカラムと言い、1行が1つのデータの単位でレコードと呼ばれる事が多いです。
わかりにくいので1レコードの例を下に書きます。
| 1 | クロスプラススタジオの歴史 | 〇〇 | クロプラ出版 | 2022-05-10 |
DBにはテーブルが複数入っており、データの種類でDBを分ける事が多いです。
ゲームにおけるDBは大まかには2種類あり
「マスタデータ」と呼ばれるゲーム内での変更が行われないデータと
「ユーザーデータ」と呼ばれるユーザーがデータを読み書きするデータです。
ゲームの実装を行うとき、ゲーム内で扱うデータの設計を
サーバエンジニアが行うことが多く、
最終的にはクライアントエンジニアや企画担当者などに設計の合意をとって決めていきます。
DB設計
先ほどのテーブルを例に設計の話をしたいのですが
先ほどのテーブルで、冗長(同じ内容)な個所があります。
著者の「neko」と出版社の「クロプラ出版」が重複しています。
もし、これらの名前が変更された時に全レコードを変更する必要が出てきます。
そういう事を考慮しテーブルを分ける事で解決していきます。
正規化後のテーブルが下記
本テーブル
| ID | タイトル | 著者 | 出版社 | 発売日 |
| 1 | クロスプラススタジオの歴史 | 1 | 1 | 2022-05-10 |
| 2 | ゲーム大好き | 2 | 2 | 2021-04-01 |
| 3 | サーバーエンジニア入門 | 2 | 1 | 2022-01-01 |
著者テーブル
| ID | 名前 |
| 1 | 〇〇 |
| 2 | neko |
出版社テーブル
| ID | 名前 |
| 1 | クロプラ出版 |
| 2 | ゲーム出版 |
このように分ける事で実際に使う際には本テーブルを軸に著者カラムに入れられているIDを使って
著者テーブルと紐付けて著者の名前を取り出せるようにします。
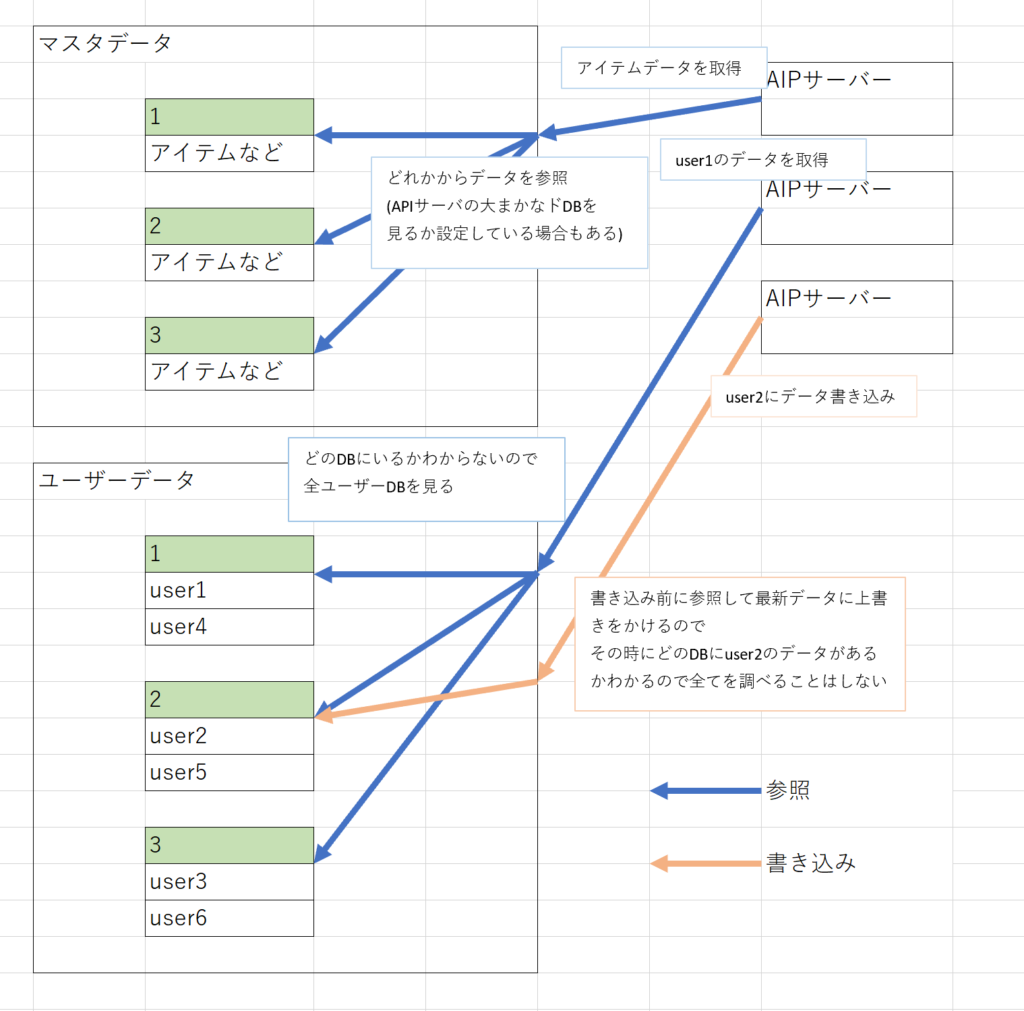
マスタデータ/ユーザーデータ
マスタデータはゲーム内で変更の発生しないデータです。
モンスターやアイテムなのステータスどゲームをプレイしていて
データを読み込むだけで書きこまれないものです。
逆に書き込みが発生するものはユーザーデータに部類されます。
ユーザーデータはゲームのプレイ中に得た経験値やアイテムの所持数など
読み込み、書き込みするデータです。
この二種類を分けておく必要がなぜあるかというと
負荷分散の面で分けておいた方が都合がいいです。
負荷分散は基本的にDB含むサーバの台数を増やす事ですが、
マスタデータは同じ内容のDBが増えるだけなのでイメージが付きやすいと思いますが
ユーザーデータに関しましては同じ内容という訳にはいかないので
各ユーザー毎にどのDBを使うかを決めており
このような分散方法をシャーディングと言います。
まとめ
DBの大まかな説明は以上になります。
ゲームでのDBのイメージはなんとなくつかめたでしょうか?
他にもインデックスやユニーク制約などなどDBの説明としては足りない部分もありますが
データを正規化して直していたり、負荷分散がどんな感じでされているかが伝われば幸いです。
次回は、、、特にネタが思いついてないので次回までに何か考えます!