
おはようございます。
エンジニアの yamamoto-mo です。
いやー暑いですね…まさに猛暑です。
もうそろそろマシになってくれないかな…と思いつつも、まだまだ続きそうですね…
コロナも油断ならないですが、熱中症も引き続き十分に気を付けていければと思います!
さて本題ですが、前回の続きで「コンピュートシェーダ」です。
結構間が空いてしまいましたね…
・GPU は大量のスレッドを利用して並列に処理が行える
・コンピュートシェーダで描画以外の用途に GPU を利用できる
この二つがある程度イメージ出来る事を、今回の記事のゴールとします。
コンピュートシェーダとは
まずそもそも コンピュートシェーダとは何かですね。
端的に述べると 並列計算処理用のシェーダ です。
シェーダというと描画処理のイメージが強いかと思います。
実際に「シェーダ」は「グラフィックスパイプラインの各プログラム」の事を指していますし、
CPU ではなく GPU で動作する物になっています。
特殊な描画表現を実現したい場合は、
まず間違いなくシェーダを自作する事になります。
GPU は CPU と違い、多数のコアを持っており、
大量の単純な計算処理を同時に行う事に長けています。
各ピクセル毎に陰影計算を行う などの働きを考えれば、
そのような特徴を持つ理由にも合点がいくのではないでしょうか。
ただその特徴は、何も描画のみに適しているわけではありません。
大量の単純な計算処理を同時に行う事であれば、
描画に直接関係ない事であっても有用になります。
そこで描画以外の並列計算処理にも GPU を利用しやすくする為に生まれたのが、
冒頭のコンピュートシェーダになります。
この辺は GPGPU というキーワードと合わせて調べて頂くと、
より理解が深まるかなと思います。
元々コンピュートシェーダは描画処理の間に差し込まれる様な動作を行っていましたが、
DirectX12 からは描画処理とも並列で動作できるようになりました。
非同期コンピュートと呼ばれる技術ですが、
これにより更に計算処理の最適化が見込めるようになっています。
(今回は載せてません…)
コンピュートシェーダの利用
今回もサンプルコードを(相変わらず適当で恐縮ですが…)用意しました。
CPU で初期化したリソースを GPU で別リソースにコピーするだけのコードです。
コンピュートシェーダも GPU で動かす物なので、
物を描画する流れと大して変わりません。
1. CPU で必要なリソースを準備して GPU に渡し
2. 渡されたリソースを利用してシェーダで処理を行い
3. その結果を別リソース(バッファ)に書き込み
4. GPU の処理が終わるまで CPU を待機させ
5. 別リソースを経由して処理結果を CPU で取得する
という流れになります。
ただ描画系の処理とは別になる為、
・コマンドリスト
・コマンドキュー
・パイプラインステートオブジェクト
などはコンピュート用の設定で作成した物を利用します。
この辺りまではわかりやすいですね。
コンピュートシェーダにおける書き込み先の指定
ここからがこれまでの描画には無かった点になるかと思います。
まず書き込み先の指定では、一般的な RenderTarget を利用しません。
コンピュートシェーダはピクセル単位ではなく、データ構造に合わせた書き込みが必要です。
またシェーダに記述する処理次第ですが、計算した結果を別の計算に再利用(読み込み)する事も珍しくありません。
その為、読み書きが可能な UnorderedAccessView を利用します。
クラスはこちらです。
コンピュートシェーダにおける並列数の指定
GPU ( シェーダ ) 側
GPU は多数のコアを持つ事により多くのスレッドを実行できる様に出来ています。
コンピュートシェーダもスレッドを用いて並列処理を実現しますが、
この並列数はシェーダコードの numthreads で指定しています。
[numthreads(4, 4, 1)] 三次元配列のイメージで捉えるのが分かりやすいです。
今回のサンプルでは「4, 4, 1」 と指定されていますが、
4 x 4 x 1 = 16 スレッドで同時に処理されるという事になります。
CPU 側
描画処理の場合 DrawXX 関数を呼び出しますが、
コンピュート処理の場合は Dispatch 関数を呼び出す事でシェーダが処理されます。
commandListCompute.get()->Dispatch(4, 4, 1); この引数も GPU 側と同じく三次元配列のイメージで捉えるのが良いと思います。
4 x 4 x 1 = 16 の指定を行っている事になりますね。
ただ GPU 側と違いスレッド数を指定しているわけではありません。
スレッドグループ数を指定しています。
スレッドグループという聞きなれない単語が出てきましたが、
これは単に 複数のスレッドをまとめたグループと認識して頂くので問題ないと思います。
ここまでの話でピンとくる方も多いかと思いますが、
1 グループのスレッド数 = シェーダで指定したスレッド数
になります。
サンプルの例だと、
グループ毎のスレッド数が 4 x 4 x 1 = 16 スレッドで
動作させるグループ数が 4 x 4 x 1 = 16 グループなので、
結果的に動作するスレッド総数は 16 x 16 = 256 スレッドになります。
コードの内容次第で並列数は制限されるので、理論値ではありますが、
「これだけの数で並列処理が出来る」と考えると、
色々な恩恵が受けられそうなのが何となく想像できるのではないでしょうか。
各 ID の利用
シェーダでは、関数(カーネル)の引数に特定のセマンティクスを指定する事で、
現在処理されている
・スレッドグループ番号(x, y, z)
・グループ内のスレッド番号(x, y, z)
・全グループ通してのスレッド番号(x, y, z)
が把握できるようになっています。
特定の位置のデータにアクセスする際に、これらの番号は頻繁に利用されます。
まずはスレッドグループ番号を指す groupID と、
グループ内のスレッド番号を指す groupThreadID です。
文章よりも図で把握した方が分かりやすいです。
※スレッドグループ数がサンプルコードと違いますのでご注意ください。
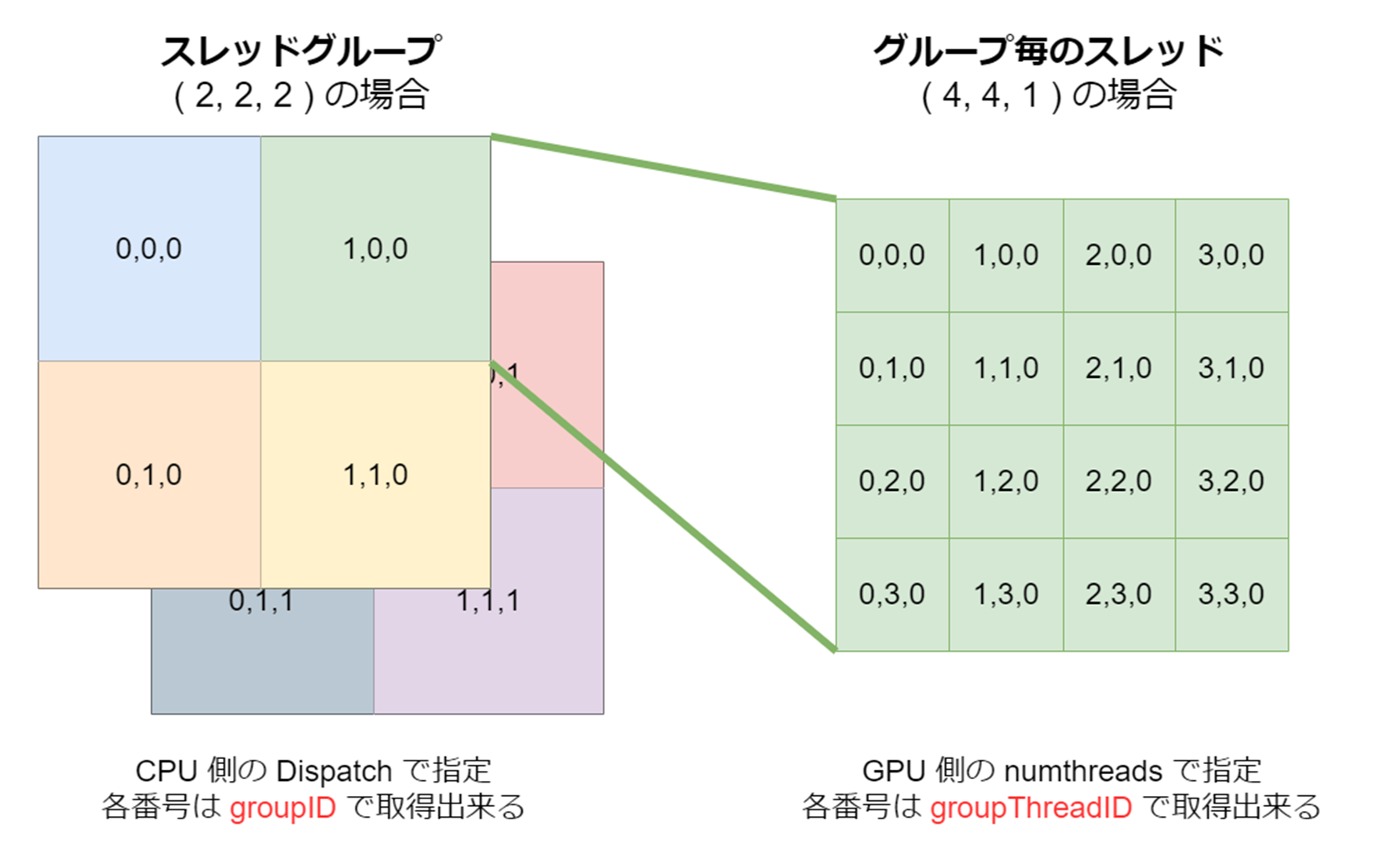
それを踏まえた上でシェーダ側のコードをご確認頂くと、
groupID と groupThreadID から、
一次元配列の添え字を計算しているのが見て取れるのではないでしょうか。
なおコメント化されている一行でも同じ添え字が計算できます。
dispatchThreadID が少しわかりにくいですが、
これが「全グループ通してのスレッド番号」です。
今回のサンプルでいうと、
・スレッドグループ数 (4, 4, 1)
・グループ毎のスレッド数 (4, 4, 1)
である為、総数は(16, 16, 1)になり、
dispatchThreadID はその範囲の値が入っている形になります。
図で表すとこの様になります。
※スレッドグループ数がサンプルコードと違いますのでご注意ください。

part 3 へ
コンピュートシェーダを使っただけの単なるバッファコピーなので、
恩恵を感じないサンプルではありますが、
・GPU は大量のスレッドを利用して並列に処理が行える
・コンピュートシェーダで描画以外の用途に GPU を利用できる
というイメージは掴めましたでしょうか。
コンピュートシェーダにはこれだけではなく、
共有メモリを利用した効率的な制御など、
今回挙げられていない事がまだまだあります。
(というか…コンピュートシェーダのコの次にすら到達してない気がする…)
…この機会に是非色々調べて頂ければと思います。
ここまで来たら次は「カリング計算を GPU で行う」に進みます。
まだまだ先は長いですね…
免責事項
掲載された内容によって生じた損害等に関して、
弊社は一切の責任を負いかねますので、予めご了承ください。